One API,
every model.
70+ leading models from 10+ vendors behind one API. OpenAI-compatible. Swap one line of base URL — invoke any model.
# Just swap base_url and api_key
from openai import OpenAI
client = OpenAI(
base_url="https://nodekey.xinghanyun.cn/v1",
api_key="sk-xxxxxxxxxxxxxxxxxxx",
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello"}],
)
print(response.choices[0].message.content)// Compatible with the OpenAI Node SDK — no other code changes
import OpenAI from "openai";
const client = new OpenAI({
baseURL: "https://nodekey.xinghanyun.cn/v1",
apiKey: "sk-xxxxxxxxxxxxxxxxxxx",
});
const resp = await client.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: "Hello" }],
});
console.log(resp.choices[0].message.content);# Native REST — fully compatible with the OpenAI spec
curl https://nodekey.xinghanyun.cn/v1/chat/completions \
-H "Authorization: Bearer $XHY_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": [
{"role": "user", "content": "Hello"}
]
}'// Go client example
import "github.com/sashabaranov/go-openai"
config := openai.DefaultConfig("sk-xxxxxxxxxxxxxxxxxxx")
config.BaseURL = "https://nodekey.xinghanyun.cn/v1"
client := openai.NewClientWithConfig(config)
resp, _ := client.CreateChatCompletion(ctx, openai.ChatCompletionRequest{
Model: "gpt-4o",
Messages: []openai.ChatCompletionMessage{{Role: "user", Content: "Hello"}},
})Models we support
10+ providers, 70+ active models. Switch provider to see live unit prices.
CNY / 1M tokens · Live prices, synced with the pricing center; pay by token, no subscription, smart routing auto-picks the cheapest fitting model.
Why Intelligent Compute Platform
Every AI call burns tokens — the token is the unit of account of the AI era. Intelligent Compute Platform unifies token aggregation, routing, metering, and settlement in one place: broadest coverage, smart routing, transparent pricing, production-grade reliability, localized service — from indie developers to enterprises, the single entry point to AI models.
Broadest reach — one interface
70+ leading models from 10+ vendors, all behind a single base URL. No more juggling separate accounts for OpenAI, Anthropic, DeepSeek, or Qwen.
Pick the right model per task
Routes by task type, context length, latency, and cost target — light models for intent classification, high-end models for code and reasoning, long-context models for long-form. The same workload can cost 30–60% less.
Transparent, pay-as-you-go
Charged on actual token usage. No subscriptions. Model prices update in real time and roll up into one invoice — easy to expense and split across teams.
Multi-vendor failover, no outages
When one model fails, routes automatically to a same-capability backup. Production SLA targets 99.99% uptime. Edge nodes route locally for lower latency.
Localized support, top to bottom
Localized documentation, WeChat/WeCom support, B2B invoicing, bank reconciliation, data-processing compliance, private deployment options. Built around what regional enterprises actually need.
From signup to first call in 5 minutes
Sign up and get an API Key
Open the console and create your API Key. Enterprise tier — talk to sales for dedicated quotas and billing.
Swap one base URL
If you already use the OpenAI / Anthropic SDK, change only the base URL and API Key. Nothing else needs to move.
Top up and start calling
Pay-as-you-go billing. The console shows usage, cost, and routing decisions in real time.
Visible usage, clear bills
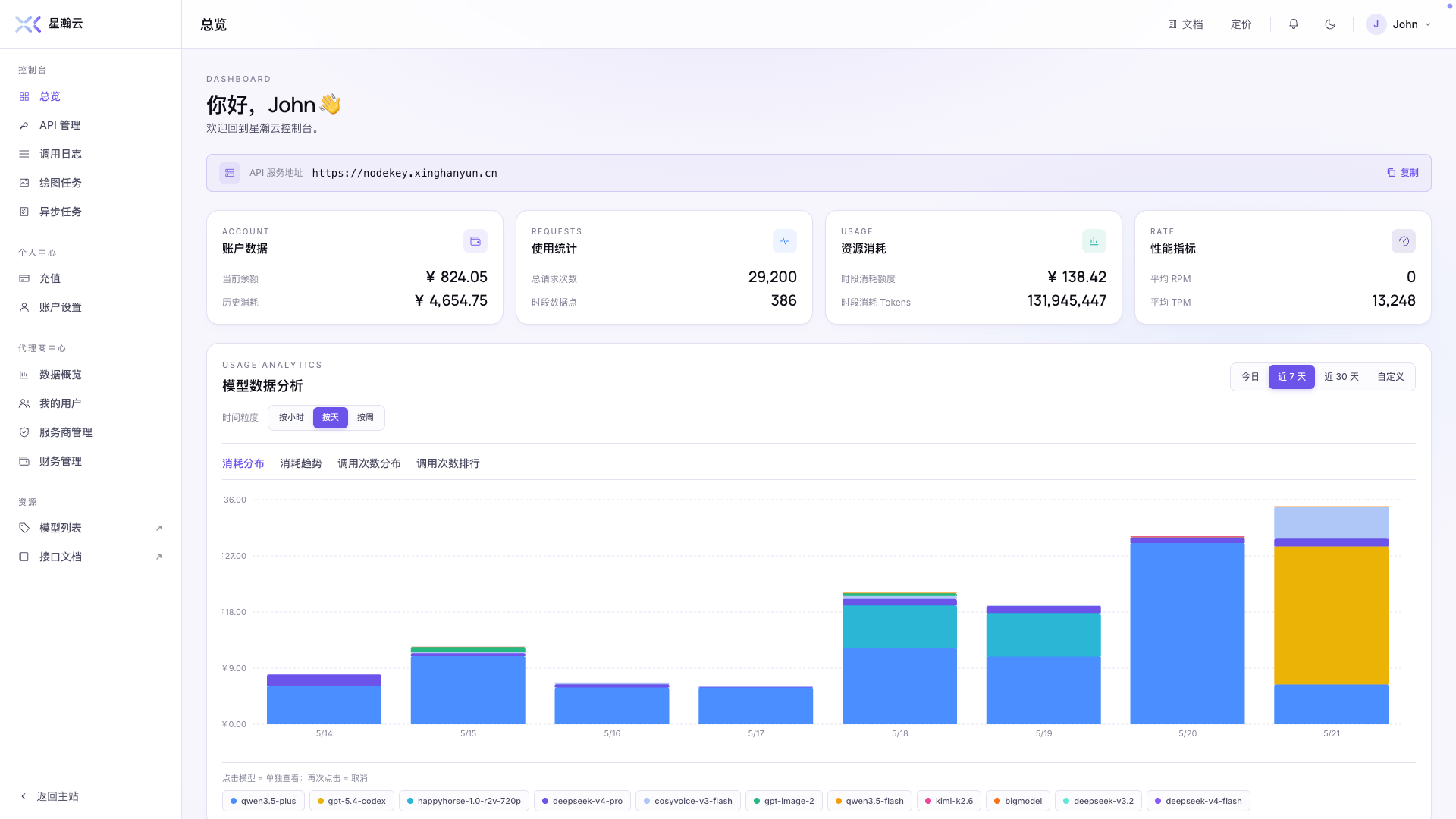
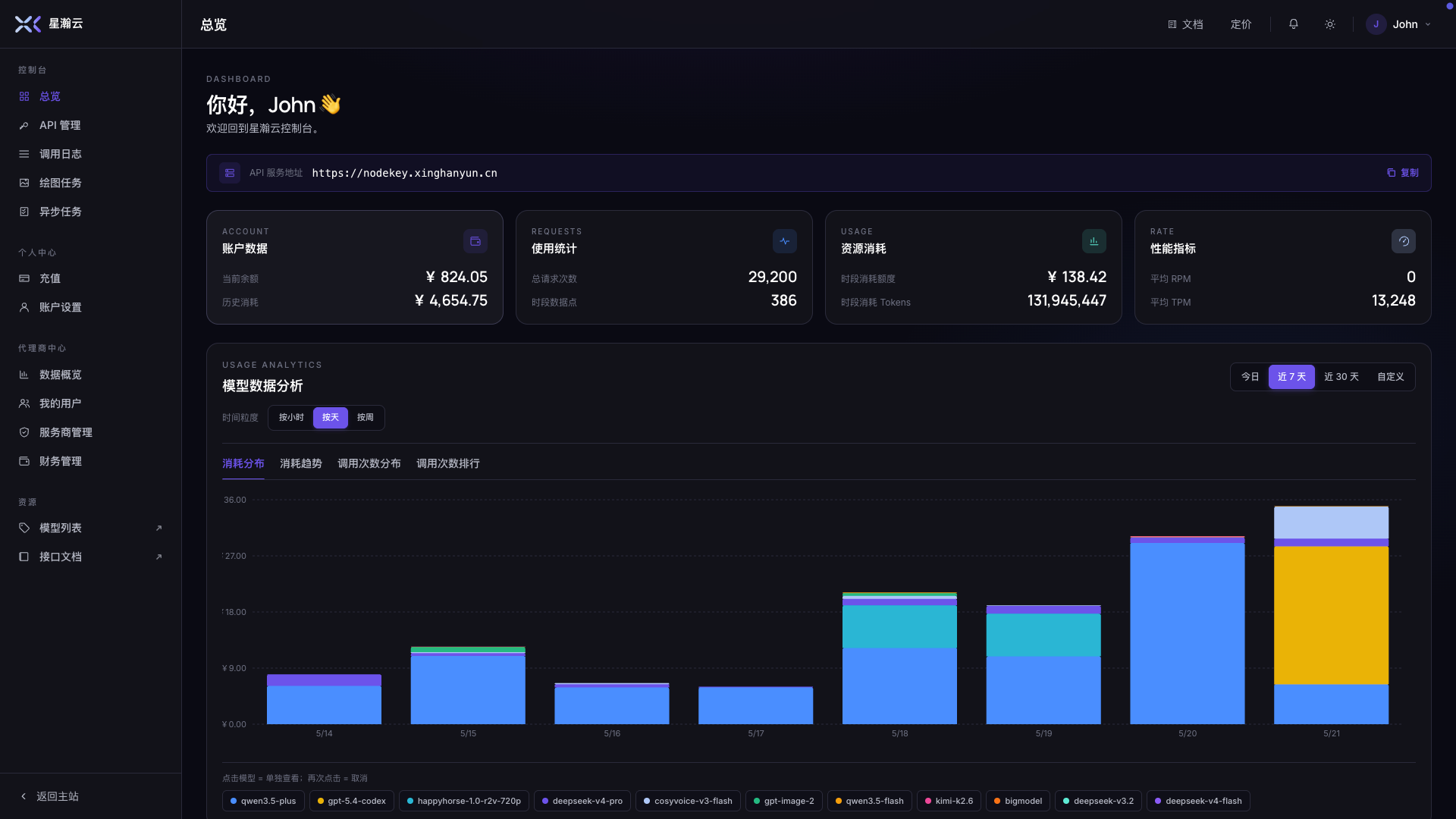
Real-time usage
See call counts and token consumption by model, project, or API key.
Cost dashboard
Roll up cross-model spend onto one invoice. Split by department, aggregate by day.
Routing observability
Per-call routing decision, latency, and success rate — all visible.
From indie developers to enterprises
Indie developers
One account for every model
- Pay-as-you-go — no subscription, no minimum
- One top-up unlocks every model
- All billing in one wallet
- 24-hour top-up & settlement
AI startups
Ship without delay, fail-over by default
- 70+ models in one integration, switchable any time
- Multi-vendor failover keeps your product up
- Usage dashboard split by project / team
- Enterprise inquiry response within 4 hours
Enterprises
Private deployment & dedicated SLA
- Dedicated cluster & private deployment
- Data redaction + compliance audit logs
- B2B invoicing, bank reconciliation, annual reports
- Security & compliance support
Enterprise capabilities
Dedicated clusters, compliance audit, B2B settlement, and private deployment for mid-to-large enterprises.
Dedicated cluster
Isolated compute pool with dedicated rate-limit policies — no noisy neighbors.
Enterprise invoicing
B2B transfers, VAT special invoices, bank reconciliation, monthly rollups.
SLA & failover drills
Production-grade availability commitment. Quarterly failover drills and DR cutover.
Data compliance
Keep data in-region, redaction in transit, audit logs, security-tier compliance support.
Private deployment
Run Intelligent Compute Platform's scheduling layer in your own IDC. Models can stay flexible (self-hosted / partner / public).
Custom routing
Routing policy tailored to your priorities — business value, region, compliance.
Developer questions
How is Intelligent Compute Platform different from OpenAI's official API? ▾
Intelligent Compute Platform is a unified model gateway — one account, one integration, 70+ models. For regional developers we add localized invoicing, B2B reconciliation, local payment methods, and compliance — removing the friction of cross-border accounts and payments.
Compatible with the OpenAI SDK? ▾
Fully. Existing OpenAI-SDK code only needs the base URL and API Key swapped — call shapes, parameters, and response formats are identical. The native Anthropic spec is also supported.
How does billing work? ▾
Per-token usage is metered consistently across models. Pay-as-you-go after a top-up — no subscription, no minimum. Enterprises get monthly reconciliation and VAT special invoices. See the pricing center for details.
Can you guarantee uptime? ▾
We target 99.99% uptime in production. The multi-vendor routing policy automatically failovers to a same-capability backup on outage — degradation happens transparently at the request level.
Is private deployment supported? ▾
Yes — the enterprise tier supports running Intelligent Compute Platform's scheduler and metering layer in customer IDCs, with model choice still flexible (self-hosted / partner / public). Talk to sales for specifics.
Will my data be used to train models? ▾
Intelligent Compute Platform itself does not store call content and does not train on customer data. Each upstream vendor's data policy applies — we evaluate compliance during onboarding.
Five lines of code to your first call
Sign up, get an API key, swap the base URL — start invoking 70+ leading models.